
Introduction
Kubernetes has become the de facto platform for modern application delivery. But beneath all the YAML files, Helm charts, and dashboards lies a foundational component that most engineers never touch — yet everything depends on it: etcd.
If you’re coming from a world where you managed critical infrastructure like Active Directory, PostgreSQL, or DNS servers, you know that systems only work when their underlying state is trustworthy and recoverable.
In Kubernetes, that “state brain” is etcd.
And whether you’re working with a fully managed cluster in GKE, or a local environment in Minikube, your ability to understand and prepare for issues around etcd is the difference between resilience and total outage.
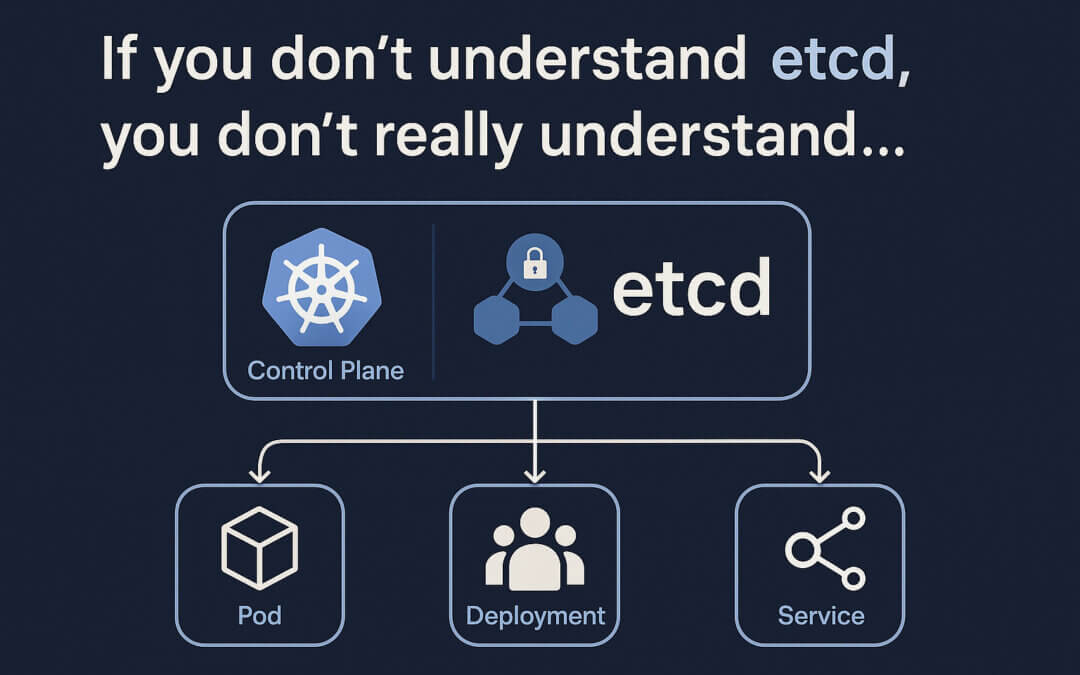
1. What is etcd, Really?
At a glance, etcd is a distributed, consistent, key-value store.
In Kubernetes, it stores:
- Every resource definition: Pods, Deployments, Services, CRDs
- Node information, roles, and conditions
- Secrets, ConfigMaps, RBAC policies
- API server state and leader election
This means etcd is the single source of truth for your entire cluster. It’s not just one component among many — it’s the foundation. Without it, your cluster cannot function.
If etcd fails:
- The API server goes blind
- Controllers stop reconciling
- Scheduling stops
- Even healthy workloads eventually drift into chaos
It’s not dramatic to say:
etcd is Kubernetes.
2. How etcd Runs Locally in Minikube
When you’re using Minikube, you’re running a single-node Kubernetes cluster — including the full control plane — on your own machine. This setup exposes the internals beautifully, especially etcd.
Here’s what happens behind the scenes:
etcdis launched as a static pod defined in
/etc/kubernetes/manifests/etcd.yaml- The kubelet, which is always running on the node, sees this file and starts the
etcdcontainer - It’s scheduled outside of the Kubernetes scheduler — it’s always there, no matter what your cluster state is
This setup allows you to:
- Read the manifest directly and see how it’s configured
- View the
etcdlogs and container process - Back up and restore its data for testing
- Simulate outages and test disaster recovery — without impacting production
You can trace the etcd container back to its Linux process using crictl:
- Run
crictl ps | grep etcdto get the container ID - Run
crictl inspect <container_id>to find the system PID - Run
ps -fp <pid>to see theetcdprocess running on your node
This is crucial for understanding that containers are just processes, and that everything Kubernetes does ultimately maps to the Linux system underneath.
3. How etcd Works in Managed Kubernetes (e.g. GKE, EKS, AKS)
When you shift to a managed Kubernetes service, things look different on the surface — but etcd is still doing the same critical job behind the curtain.
In services like GKE:
- The control plane is abstracted away — you can’t see the nodes running
etcd - You don’t manage
etcd, the API server, or control plane components directly - You can’t SSH into those nodes or inspect
etcdlogs
But here’s the catch:
Just because you can’t see
etcd, doesn’t mean you’re not responsible for its availability.
In GKE:
- Google runs a hardened
etcdcluster behind your Kubernetes API endpoint - Backups may or may not be taken depending on your tier (Autopilot, Standard, etc.)
- SLAs around control plane uptime vary — but you still bear the operational risk of downtime, corruption, or quota exhaustion
The control plane (and etcd in particular) is a shared responsibility:
You don’t run it, but your workloads and business depend on it.
4. Why Local Practice with etcd Builds Cloud Competency
Engineers who rely entirely on cloud-managed clusters often lack the intuition needed to design resilient systems.
Local environments like Minikube, kind, or kubeadm give you:
- A sandbox to break and fix
etcd - A way to see how failure propagates
- A testbed to experiment with backups, restores, and scaling
By working with etcd locally, you learn:
- How to inspect its data directory
- What happens when the API server loses connection to
etcd - How to simulate corruption or snapshot recovery
- How RBAC, CRDs, and object status are persisted
This knowledge directly helps you in cloud environments:
- Knowing what metrics to watch (
etcd_server_has_leader,etcd_disk_wal_fsync_duration_seconds) - Understanding how state consistency issues may originate from
etcd - Recognizing the symptoms of degraded performance or quota exhaustion in the API
5. etcd and the Active Directory Analogy
Let’s bring this back to a familiar pattern.
If you’ve ever managed Active Directory, you know:
- It’s the source of truth for identity and policy
- You plan domain controller redundancy
- You back it up regularly
- You monitor it constantly
- If it fails, everything stops working
Now imagine you move to Azure and use Azure Active Directory. Do you stop caring about AD because Microsoft “runs it”? Of course not. You:
- Understand its structure
- Know where your risks are
- Demand clear SLAs
- Know what could go wrong and what your business impact would be
etcd deserves the same mindset in Kubernetes. Just because it’s “managed” doesn’t mean it’s “invisible.”
6. The Risks of Treating etcd Like a Black Box
Many engineers:
- Don’t know where
etcdstores its data - Never consider what happens if it gets corrupted
- Rely entirely on cloud providers to “just handle it”
This leads to:
- Poor backup and restore planning
- Unclear expectations during outages
- Blind spots in root cause analysis
The most resilient Kubernetes teams know:
You don’t need to manage
etcdday-to-day, but you must understand it deeply.
Conclusion: etcd Is Not Optional Knowledge
If you want to master Kubernetes — not just use it — you must understand the core.
Remember:
etcdis the source of truth for your cluster- Even in managed services, your architecture relies on its health
- Local environments like Minikube offer the best way to learn how it behaves
- A production-ready mindset means knowing your dependencies, not just assuming they’ll work
Kubernetes is only as resilient as your understanding of its foundations.
And there is no foundation more critical than etcd.