
🚀 From VMware to Containers: Understanding Linux Namespaces and cgroups for DevOps Engineers
🧭 Introduction
So you’re coming from a VMware ESXi world. You’re used to spinning up VMs, assigning CPU, RAM, storage, virtual NICs, and keeping everything nicely segmented and manageable. Now everyone’s talking about containers, and terms like namespace, cgroups, Docker, and Kubernetes are flying around like they’re obvious.
Here’s the reality: everything you already know about isolation, resource control, and infrastructure boundaries is still relevant. It’s just implemented differently. This post explains how Linux namespaces and cgroups form the foundation of containers, and how they compare to the VM model you’re already comfortable with.
Let’s bridge the conceptual gap — from VMs to containers — so you can confidently operate in both worlds.
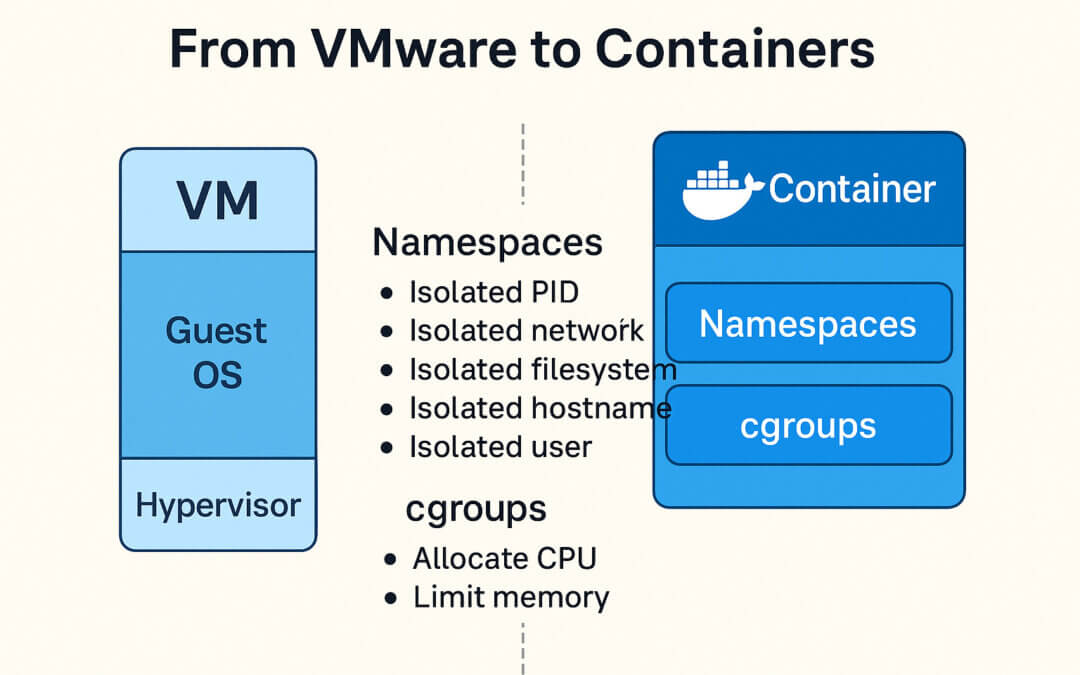
🧱 Virtual Machines vs. Containers — A Mindset Shift
Let’s start with a side-by-side comparison to get a feel for how the mechanics differ:
| Feature | VM (VMware ESXi) | Container (Docker/Linux) |
|---|---|---|
| OS Kernel | Each VM runs its own OS kernel | All containers share the host kernel |
| Boot time | Full OS boot sequence | Starts instantly like a process |
| Resource assignment | CPU, RAM, disk via hypervisor | Controlled with cgroups |
| Isolation | Hypervisor-level (hardware-level) | Namespaces (kernel-level) |
| Filesystem | Virtual disk images (VMDK, etc.) | Layered file systems (UnionFS, OverlayFS) |
| Networking | Virtual NIC, vSwitches | Virtual Ethernet pairs (veth), bridges |
| Management | vCenter, vSphere | Docker CLI, Kubernetes, systemd-nspawn, etc. |
You could say:
VMs simulate a whole machine. Containers simulate just enough of one.
🔍 Namespaces: The Illusion of a Private OS
In VMware, every VM has a complete operating system, its own kernel, and complete separation. Containers don’t go that far — instead, they use namespaces, a Linux kernel feature that provides process-level isolation.
Think of a namespace as a lens. A process inside a namespace sees only what that namespace exposes — like wearing VR goggles that show you only your private world.
🧱 Types of Namespaces (with VM Analogies)
| Namespace | Isolates | VM Analogy |
|---|---|---|
pid |
Process IDs | Each VM has its own process table |
net |
Network interfaces, IPs | Each VM has its own NIC, firewall rules |
mnt |
Filesystems and mount points | Each VM mounts its own drives |
uts |
Hostname & domain | Each VM has its own hostname |
ipc |
Shared memory, semaphores | Each VM has its own IPC space |
user |
User/group IDs | Each VM has its own user accounts and root users |
Processes in one namespace can’t see or touch resources in another. This is what lets containers believe they’re the only thing running — even though they’re just processes.
It’s not fake. It’s kernel-enforced isolation without the overhead of emulating hardware.
🎛️ cgroups: Controlling What They Can Use
Namespaces provide isolation, but cgroups (control groups) provide resource control.
Just like you assign 4 vCPUs and 8 GB RAM to a VM, you can assign CPU shares, memory limits, and IO throttling to containers. But instead of a hypervisor, the Linux kernel does it directly.
🧰 What You Can Control with cgroups
| Resource | cgroup controller |
|---|---|
| CPU usage | cpu |
| CPU pinning / affinity | cpuset |
| Memory usage / limits | memory |
| Disk I/O | blkio |
| Device access | devices |
| Number of processes | pids |
| Freezing/suspending processes | freezer |
For example, a container can be limited to:
- 256 MB RAM
- 20% of a CPU core
- 2 MB/s disk throughput
This prevents noisy neighbors and helps with capacity planning — same goals you had with vSphere resource pools, just done differently.
⚙️ Behind the Scenes: What Happens When You Start a Container?
Let’s demystify what Docker (or Kubernetes, or runc) actually does when you start a container.
- Fork a new process from a base image (like
ubuntu:20.04) - Apply namespaces: give it its own PID, mount, net, user views
- Apply cgroups: cap its CPU, RAM, and IO
- Set up a filesystem using UnionFS (overlaying layers like
base + app + config) - Set up networking: attach to a virtual bridge or overlay network
- Run your process (e.g.,
nginx,node,java)
That’s it. The entire “container” is just a process with new glasses and a leash.
🛠️ What Containers Don’t Give You (Compared to VMs)
- You can’t run another OS kernel (unless using something like Kata containers or gVisor)
- You don’t get a BIOS, EFI, or firmware
- You don’t install drivers
- You’re still tied to the host’s kernel (and its version)
So while containers are lightweight, fast, and scalable — they are not a full replacement for VMs in every scenario. For example:
- You can’t run Windows containers on a Linux host (without a VM)
- You can’t test a new kernel inside a container
- You don’t get strong isolation guarantees (containers share kernel space)
🧠 DevOps Takeaways
From a DevOps perspective, here’s what matters:
- Containers scale faster and pack tighter than VMs
- You still control resources: via cgroups, limits, requests (in Kubernetes)
- Monitoring changes: You track host metrics, per-container metrics (e.g. using
cAdvisor,prometheus,docker stats) - Debugging changes:
top,ps,strace,netstat— all done from the host or inside the container namespace - You gain powerful new tools like:
nsenter– enter a namespacerunc– low-level container executioncgroupfs– inspect resource limits directly
🔚 Final Thoughts: Think Small, Act Big
So yes — you can think of each container as a mini-VM. It has its own view of the world, its own boundaries, and its own leash. But it starts in milliseconds, consumes kilobytes, and doesn’t pretend to be a whole machine.
If VMware ESXi gave us heavy-duty machinery, containers give us ultra-light drones — fast, nimble, and perfect for modern workloads.
Once you understand how namespaces provide isolation and cgroups provide control, you’re no longer just using containers — you’re mastering them.